
作为小白,你只需要知道一个核心逻辑:“龙虾”的记忆本质上是它工作空间里的 Markdown 文本文件。
只要写进了文件,即便重启,它也永远不会忘。
原生记忆致命的痛点: OpenClaw 的记忆是扁平的文本
如果你在这个月告诉它“我老婆叫小红”,下个月告诉它“小红对花生过敏”,当你想让它 “帮我订一家适合我和老婆吃饭的餐厅” 时,原生记忆可能无法立刻把这三件事串联起来。
简单来说,原生记忆像是一个“带有自动摘要功能的记事本”,而我们真正需要的是一个“具备自我进化能力的动态大脑”。
除非你的只是赶潮流, 搭建一个 “玩具龙虾🦞” , 它不能真正的帮你 “赚钱” 或者 “提高生产力”。
据了解 , 未搭建必要系统的 Open Claw 用户, 大多数会耗费大量的时间反复调整修复自己 “低能龙虾” 。
要成为超级个体, 搭建 Open Claw 必然是为了让它帮我们赚钱的。 从一开始,我们就要构建专业生产级别的 Agent 系统, 将其视为一种 “资产” 而非AI工具。
为什么龙虾又蠢又贵?
—
在 AI 应用中,“原生记忆”(即把历史对话作为上下文直接塞进大模型的 Prompt 里)只能用于玩具级别(Toy-level)或概念验证(PoC)阶段。
一旦进入生产环境,Mem0 和 SuperMemory 是目前业内最主流、最受推崇的两大生产级记忆基础设施。
以下几个维度来看为什么必须升级,这两个工具在生产环境中该如何选择:
“原生记忆”无法胜任生产级?
—
-
成本失控(Token 燃烧机)
原生记忆需要每次对话都带上前文。如果一个用户与 AI 聊了半年,每次提问都要带入数万 Tokens 的历史记录,API 调用成本将是灾难性的。
-
延迟极高
处理 50k Tokens 的上下文和处理 1k Tokens 的上下文,模型的首字响应时间(TTFT)有天壤之别,严重影响用户体验。
-
“迷失在中间”
即便是拥有超大上下文窗口的模型,也会在庞杂的聊天记录中遗漏关键信息或产生幻觉。
Mem0 和 SuperMemory
—
虽然它们都是解决“长期记忆”的生产级方案,但它们的设计理念和适用场景有非常明显的区别:
1. Mem0:开发者主导的“记忆数据库” (主打:精准控制)
Mem0(前身是 Embedchain 团队)的哲学是:记忆必须是明确的、可控的、可审计的。
-
核心逻辑
它将记忆转化为可执行 CRUD(增删改查)的具体对象。当用户说话时,Mem0 仅提取核心事实(例如:“用户对海鲜过敏”),并将其作为独立的记忆词条存入向量数据库。
-
优势
-
极省成本与低延迟
根据其在 2026 年初发布的 LOCOMO 基准测试,Mem0 通过精准检索,比传统原生全上下文方法节省了 90% 的 Token,延迟降低了 91%。
-
透明可查
开发者可以清晰地看到 AI 到底记住了什么,随时手动修改或删除。
-
-
生产级场景
企业级 SaaS、智能客服、医疗/金融助理。在这些场景中,开发者需要对 AI 的记忆边界有绝对的控制权,不能允许 AI 瞎关联。
2. SuperMemory:全自动的“外挂认知引擎” (主打:像人脑一样自动推理)
SuperMemory(由知名开源开发者 Dhravya Shah 创立)的哲学是:记忆应该像人类大脑一样,在后台自动发生、自动遗忘、自动连接。
-
核心逻辑
它不仅仅是存数据,而是在底层构建知识图谱,并抽象为“用户画像(User Profile)”。你不需要写复杂的提取逻辑,只需将它配置为“Memory Router(记忆路由器)”代理大模型的请求。
-
优势
-
高度自动化
它会自动处理知识矛盾(比如昨天说喜欢喝咖啡,今天说戒咖啡了,它会自动覆盖)、自动遗忘不重要或过期的信息。
-
自带生态连接器
原生支持一键接入用户的 Notion、Google Drive 或 OneDrive 文件,直接将其化作 AI 的潜意识背景。
-
生产级场景
个人超级助理(Personal AI)、C 端情感陪伴机器人、复杂的长时间线多智能体系统。在这些场景中,开发者希望实现“无感接入”,让 AI 自己去察言观色和做笔记。
根据你的应用是对“控制力”要求更高,还是对“自动化认知” 要求更高,在这两者中选择一个,是迈向 2026 年生产级 AI 应用的必经之路。 (注意不必两个同时安装, 容易导致重复的Token消耗)
Mem0
—
Mem0(目前业界非常流行的专业级 AI 记忆层),那么 Mem0 确实拥有几个原生文件记忆无法比拟的绝对优势。

-
Mem0 带来的核心绝对优势: 真正的“关联推理”能力(知识图谱 + 向量双重架构)
-
Mem0 的绝对优势
它引入了图谱记忆(Graph Memory)。它不仅记录事实,还记录实体之间的“关系网络”。它能像人类一样自动推理出“你老婆 = 小红 = 不能吃花生”,从而直接避开花生相关的餐厅。
2. 节省约 90% 的 Token 成本并大幅降低延迟
-
原生记忆的痛点
当你的 OpenClaw 聊天记录越来越长,原生记忆会触发“压缩(Compaction)”或者直接把一大坨文本塞进 AI 的上下文里。 这会导致两个问题:一是每次对话都在烧大量的 Token(如果你用的是付费 API 的话),二是 AI 处理的信息太多,回复变慢。
-
Mem0 的绝对优势
Mem0 采用了极其精准的动态检索。它只会在数据库中提取当前对话绝对需要的那一小片记忆。根据其公开的测试数据,相比于传统的全上下文填充,Mem0 能降低约 90% 的 Token 消耗,并让响应速度(p95 延迟)提升 91%。
3. 全自动的“自我进化”与“记忆新陈代谢”
-
原生记忆的痛点
经常需要你手动干预,比如命令它“把这句记下来”。如果你的喜好变了(比如以前喜欢喝拿铁,现在改喝美式),如果不手动删掉旧的 Markdown 记录,AI 可能会产生混乱。
-
Mem0 的绝对优势
它是一个自适应(Self-Improving)系统。你在日常自然聊天时,它会在后台默默分析并自动更新你的偏好。它懂得“覆盖”和“遗忘”——如果发现你最新的习惯发生了改变,它会自动修正底层的记忆逻辑,永远保持最新的状态,不需要你打开文件去修改。
4. 结构化的多层级记忆体系
-
原生记忆的痛点
所有重要规则、过往聊天历史、事实偏好都容易混在一起。
-
Mem0 的绝对优势
它在底层将记忆严格划分为了四个维度:
-
短期记忆
(Short-term):管理当前这次互动中的临时信息。
-
长期记忆
(Long-term):跨越所有会话的永久偏好。
-
语义记忆
(Semantic):你教给它的概念和知识。
-
情景记忆
(Episodic):对过去某次具体事件的回忆(例如:“上次你帮我写那封道歉信的时候…”)。 这种结构让 AI 面对极其复杂的连续提问时,依然能保持清晰的逻辑。
-
什么时候该换 Mem0?
你使用 OpenClaw 一段,发现它开始“记混事情”、“每次回复需要等很久”、“API 账单越来越贵”,或者你不再满足于一个“备忘录助手”,而是想要一个能完全读懂你心思的“终极数字管家”时,那就是你花时间去配置 Mem0 的最佳时机。
SuperMemory
—
SuperMemory 是一个专为 AI 系统设计的结构化记忆增强框架(MemoryOS + APIs + SDK + Agents),被誉为“AI 时代的第二大脑”,它通过图谱化记忆和插件化设计,提供比 Mem0 更强的长期跨会话推理和分布式扩展能力。
与 Mem0 和原生 Markdown 的对比
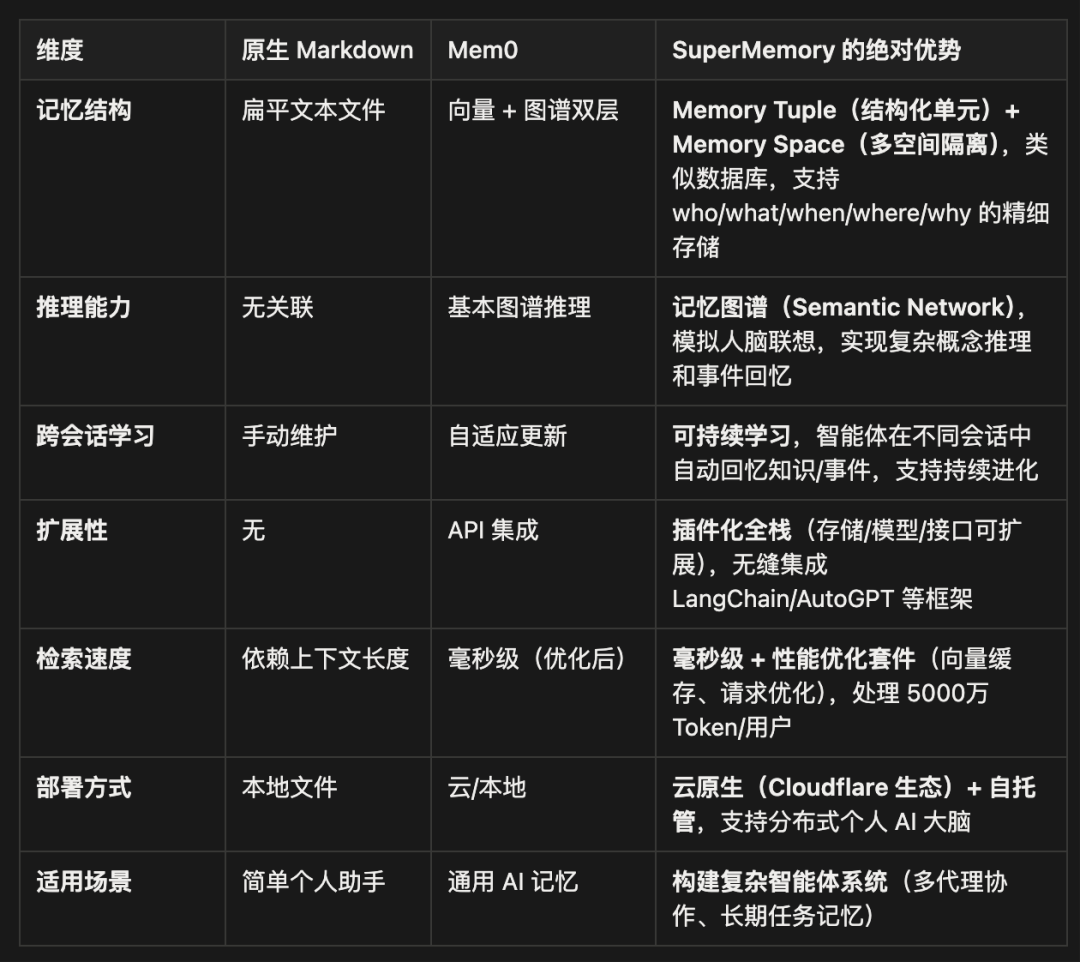
SuperMemory 的核心绝对优势
-
类操作系统级的记忆管理
不像 Mem0 是单一记忆层,SuperMemory 管理多个 LLM 智能体的“语义记忆”,支持按任务/时间/上下文分隔的 Memory Space,避免记忆冲突。
-
图谱驱动的深度推理
通过记忆图谱,它能自动构建实体关系网络。例如,如果你保存了“项目 A 用 React,项目 B 遇到 React Bug”,它能推理出“项目 B 可参考项目 A 的解决方案”——这远超 Mem0 的基本关联。
-
高吞吐量生产级性能
每日处理超 50 亿 Token,毫秒级响应;内置优化(如向量余弦相似度缓存),适合重负载场景。
-
多模态输入 + 智能对话
支持网页/PDF/笔记一键保存,自然语言检索(如“总结上周 AI 文章”),并生成 AI 洞察/写作辅助。
SuperMemory 不是简单“记忆工具”,而是构建具备人类级长期记忆的 AI 智能体基础设施,特别适合开发者/重度用户。
记忆系统的成本
—
这两家针对开发者和个人 AI Agent 的定价策略非常相似:起步都是完全免费的,并且主流的高级个人版都是 19 美元/月。
对 90% OpenClaw 用户来说,直接使用两家的免费额度就完全足够了。
1. Mem0 定价
Mem0 是目前在 Agent 圈子里最成熟的记忆方案之一,它的计费主要基于“记忆条数”和“检索次数”。
-
Free(免费版):$0 / 月
-
额度:可存储 10,000 条记忆,每月支持 1,000 次 API 检索调用。
-
适用场景:足够覆盖日常的个人聊天。如果你每天和 OpenClaw 对话 30 次,每个月差不多就是 1000 次检索。
-
-
Pro(专业版):$19 / 月
-
额度:大幅提高检索次数,且底层支持更复杂的图谱记忆(Knowledge Graph),AI 能更好地理解人、事、物之间的关联。
-
-
Team/Enterprise(团队与企业版):$249 / 月起
-
额度:针对大用量平台或需要高合规性(SOC 2 等)的企业。
-
-
补充
Mem0 是开源的,如果你的宿主机性能足够,完全可以脱离它的云端,自己本地免费部署 Mem0 引擎。
2. Supermemory 定价
Supermemory 更偏向于“语义搜索引擎”和“第二大脑”,它的计费核心主要看“处理了多少 Token”以及“搜索次数”。
-
Free(免费版):$0 / 月
-
额度:每月可处理 100 万 Token 的数据摄入,支持 10,000 次搜索查询。
-
适用场景:它的搜索额度给得非常慷慨。如果你喜欢给 OpenClaw 发送大量的长文章、URL 或 PDF 让它记住,这个版本对普通人非常宽裕。
-
-
Pro(专业版):$19 / 月
-
额度:每月 200 万 Token 处理量,100,000 次查询,并提供“私有内存分区”(适合你同时运行多个互相隔离的 Agent 时使用)。
-
-
Scale(扩展版):$399 / 月
-
额度:高达 8000 万 Token 摄入和 2000 万次搜索,并配备专属支持服务。
-
关键提醒
—
💡 一个关键提醒:记忆插件实际上是在“帮你省钱”
虽然讨论的是记忆插件的费用,但你需要知道:OpenClaw 本身是免费开源的,你真正需要自掏腰包的最大成本,是你绑定的底层大模型 API 费用(例如 Anthropic 的 Claude 3.5 Sonnet,每百万输入 Token 大约收费 3 美元,输出收费 15 美元)。
如果你不安装任何记忆插件,OpenClaw 默认会采用“全量上下文(Full Context)”的模式——也就是每次你跟它说话,它都要把你过去所有的聊天记录打包发给大模型重新读一遍
随着聊天记录变长,你的 Token 费用会呈指数级暴涨。
安装 Mem0 或 Supermemory 的真正意义在于“上下文压缩”:
当你接入这些记忆库后,系统会在每次对话时,只从记忆库里提取最相关的几句话(也就是 RAG 检索),而不是几万字的全部聊天记录。
开发者实测指出,这通常能帮你节省 90% 左右的大模型 API Token 开销。

安装教学
—
为 Open Claw 设计出海战略中的“长期记忆系统”,是将其从“单次对话的工具”升级为“懂用户、有连贯性且高度个性化的智能体(AI Agent)” 的关键一步。
在出海场景下,面对跨语言、跨时区、多元文化以及高昂的 API 算力成本,选择合适的记忆层至关重要。
我们来看如何安装他们:
Mem0 的核心在于通过 API 主动管理实体的记忆状态。
1 官网 KEY 获取https://app.mem0.ai/
2 skill 技能安装
# 方法一 直接下载文件 zip , 发送给 Open Claw 让它安装。
https://clawhub.ai/abhayjb/mem0
# 方法二 在终端执行命令
npx clawhub@latest install mem0
3 让Open Claw 测试是否成功,检查节省 Token
Supermemory 提供了极其优雅的 Router 模式,直接接管记忆。
1 官网 KEY 获取https://console.supermemory.ai/
2 skill 技能安装
# 方法一 直接下载文件 zip , 发送给 Open Claw 让它安装。
https://clawhub.ai/clawdbot51-oss/supermemory
# 方法二 在终端执行命令npx clawhub@latest install supermemory
3 让Open Claw 测试是否成功,检查节省 Token
战略价值
—
对于准备出海的 Open Claw 而言,引入这两个系统主要解决以下三大痛点:
1. 突破跨文化语境与“遗忘”瓶颈,打造极致的本地化体验
出海产品面对的是全球多元化的用户群体。如果没有长期记忆,Open Claw 每次交互都需要用户重复说明其文化背景、语言偏好或业务诉求。
-
价值
使用 Mem0 或 Supermemory,Open Claw 可以永久记住诸如“欧洲用户注重隐私保护,需规避敏感数据”、“拉美用户习惯使用更热情的寒暄语”等信息。这种连贯性能显著提升用户粘性和满意度。
2. 大幅降低海外算力成本(降本增效)
海外商业大模型(如 GPT-4, Claude 3.5)的 Token 计费相对较高。如果依靠每次将整个对话历史塞入 Prompt 来保持“记忆”,随着时间推移,成本将呈指数级增长,甚至触发模型上下文上限限制。
-
价值
这两款系统都具备高度智能的上下文提炼能力。Supermemory 的自动路由和 Mem0 的智能合并,可以确保只将高度相关的记忆传递给 LLM。这种机制能为你节省高达 70%∼90% 的 Token 成本支出。
3. 打破数据孤岛,快速融入海外 SaaS 生态
海外市场的业务流转高度依赖成熟的第三方平台(Slack, Discord, Google Workspace 等)。
-
价值
Supermemory 对 MCP 的原生支持,就像为 Open Claw 开启了跨平台的“蓝牙”连接。这意味着 Open Claw 可以直接读取和记忆散落在各种海外应用中的知识和历史,极大缩短了研发团队分别去对接不同平台 API 的周期。
4.安全保障
本地的记忆系统依然保留的, 这样对于敏感信息会存在本地, 而脱敏数据保留在云端记忆中。
点睛之笔
—
-
如果 Open Claw 的核心定位是“拟人化 AI 伴侣”或“复杂决策的 AI 代理(Agent)”
需要构建用户画像、理解实体间的网络关系(比如用户与公司的关系、兴趣之间的关联),建议深度集成 Mem0,利用其强大的图谱记忆(Graph Memory)能力。
-
如果 Open Claw 是面向生产力、非结构化知识处理,或者希望以最快速度为现有的长对话功能外挂一个记忆系统
,建议直接使用 Supermemory 的 Memory Router,其零代码替换特性和跨应用生态将大幅缩短出海产品的上线时间。
最好,再安装一个自我进化 技能 skill
https://clawhub.ai/ivangdavila/self-improving
这样,当你的 Open Claw 做的不对的时候, 他会自我纠正, 并吸取教训, 越用越聪明。
如果你希望学到更多实用的技能, 欢迎联系我们 :
视频教学: https://www.youtube.com/@0xcii
培训咨询: https://t.me/AturX
